Polars에서 Data Type과 Structure
데이터 타입
Polars는 다양한 데이터 타입을 지원하며 모든 결측값을 NaN이 아닌 null로 표현한다.
숫자 데이터 타입
- Signed Integers(부호가 있는 정수)
- Int8, -128~127
- Int16, -32768 ~ 32767
- Int32, -2147483648 ~ 2147483647
- Int64, -9223372036854775808 ~ 9223372036854775807
- Unsigned Integers(부호가 없는 정수)
- UInt8, 0 ~ 255
- UInt16, 0 ~ 65535
- UInt32, 0 ~ 4264967295
- UInt64, 0 ~ 18446744073709551615
- Floating point numbers(부동소수점)
- Float32, 단정밀도
- Float64, 배정밀도
- decimals
- 선택적 정밀도와 음수가 아닌 값을 표현하는 128-bit의 10진수로 Python의 decimal과 같음
중첩 데이터 타입
- List
- 모든 요소의 데이터 타입이 같고 가변 길이의 1차원 리스트
- Struct
- Python의 Dictionary나 typing.TypedDict와 비슷하게 한 열에 여러 필드를 저장
- Array
- 고정된 길이를 가진, Numpy 배열과 유사한 배열
시간에 관련된 데이터 타입
- Date
- 날짜를 표현
- Datetime
- 날짜와 시간을 표현
- Time
- 시간을 표현
- Duration
- 기간을 표현
기타
- String
- 가변길이의 UTF-8 인코딩 된 문자열 데이터
- Binary
- 임의의 다양한 길이의 원시 바이너리 데이터
- Boolean
- boolean 타입
- Categorical
- 런타임에서 추론되는 문자열 분류들의 효율적이게 인코딩
- Enum
- 미리 정해진 문자열 분류 집합을 효율적이고 순서 있게 인코딩
- Object
- 임의의 Python 객체
구조체
Series
Series는 모두 같은 데이터타입을 가진 1차원의 데이터 구조로 Polars는 값으로부터 데이터타입을 추론한다.
특별한 데이터타입을 지정하는 것도 가능하다.
import polars as pl
s = pl.Series("ints", [1, 2, 3, 4, 5])
print(s)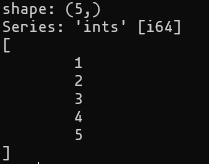
# dtype으로 데이터타입 선언
s1 = pl.Series("ints", [1, 2, 3, 4, 5])
s2 = pl.Series("uints", [1, 2, 3, 4, 5], dtype=pl.UInt64)
print(s1.dtype, s2.dtype)
DataFrame
DataFrame은 고유한 이름을 가진 Series들이 포함된 데이터타입의 2차원 데이터구조이다.
데이터를 DataFrame에 보관하면 Polars API를 사용하여 데이터를 조작하는 쿼리를 작성할 수 있다.
Series와 같이 DataFrame을 만들 때 Schema를 추론하고, 필요하다면 덮어쓸 수 있다.
from datetime import date
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
date(1997, 1, 10),
date(1985, 2, 15),
date(1983, 3, 22),
date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
Schema
Schema는 Column 또는 Series의 이름과 그 컬럼의 데이터 타입의 매핑 정보이다.
print(df.schema)
Python에선 Dictionary를 사용하여 컬럼명과 데이터타입을 정의할 수 있는데 schema 파라미터 사용 시 모든 컬럼을 입력해줘야 한다. 이때 데이터 타입에 None을 입력하면 해당 컬럼은 덮어쓰지 않는다.
df = pl.DataFrame(
{
"name": ["Alice", "Ben", "Chloe", "Daniel"],
"age": [27, 39, 41, 43],
},
schema={"name": None, "age": pl.UInt8},
)
print(df)

모든 컬럼을 override 해야 하는 불편함이 있어 특정 컬럼의 schema만 변경할 땐 schema_overrides 파라미터에 원하는 컬럼과 데이터타입만을 매핑하여 사용하는 것이 편하다.
df = pl.DataFrame(
{
"name": ["Alice", "Ben", "Chloe", "Daniel"],
"age": [27, 39, 41, 43],
},
schema_overrides={"age": pl.UInt8},
)
print(df)
DataFrame 확인
DataFrame을 빠르게 확인하기 위해 pandas와 비슷하게 몇 가지 함수를 지원한다.
- head
- DataFrame.head(n)
- 인자로 입력한 개수만큼 상위 N개의 row를 출력하며, default는 5개이다.
- tail
- DataFrame.tail(n)
- 인자로 입력한 개수만큼 하위 N개의 row를 출력하며, default는 5개이다.
- glimpse
- DataFrame.glimpse(...)
- 조금 다른 함수로, 각 컬럼 별 처음 몇 로우를 보여주지만 head와 포맷이 다르다.
- 한 컬럼당 한 열씩 사용하며 컬럼당 N개의 로우 출력, defaulit는 10개이다.
- return_as_string을 True로 준다면 stdout 대신 string으로 반환한다.
- sample
- DataFrame.sample(n, ...)
- 말 그대로 무작위 샘플 데이터 추출이다.
- seed 파라미터를 통해 무작위가 아닌 일정 샘플 추출이 가능하다.
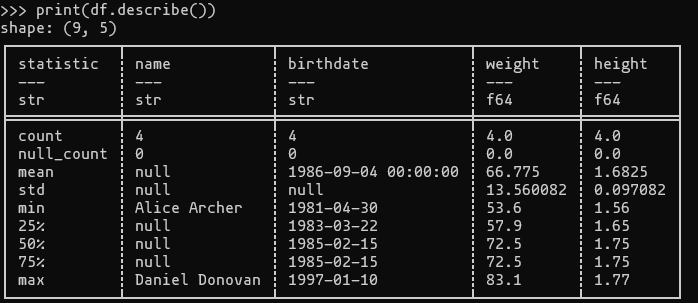
- describe
- DataFrame.describe(...)
- 모든 컬럼에 대한 요약 통계를 볼 수 있다.
from datetime import date
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
date(1997, 1, 10),
date(1985, 2, 15),
date(1983, 3, 22),
date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df.head(3))
print(df.tail(3))
print(df.glimpse(return_as_string=True))
print(df.glimpse())
print(df.sample(2, seed=42))
print(df.sample(2))
print(df.describe())




마무리
이번엔 Polars의 데이터 타입 및 구조체들, 간단히 DataFrame을 확인하는 방법에 대해 알아보았다.
다음번엔 Polars의 표현식과 Context에 대해 알아보겠다.
참고자료