
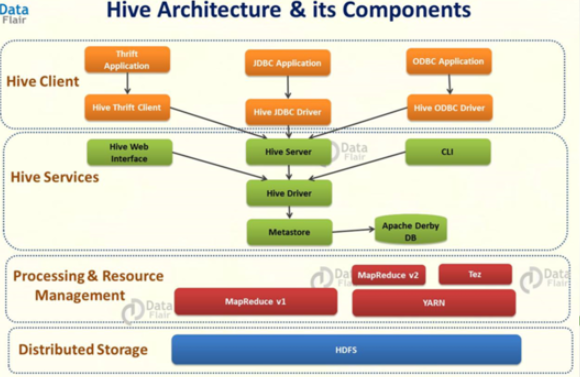
Hive의 메타데이터를 저장하는 db를 durbyDB를 MySQL로 바꿀 예정
dn01에서 MariaDB실행
# mysql -u root -p
로 로그인
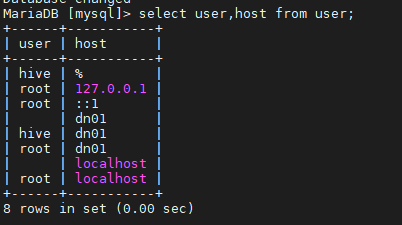
> grant all privileges on *.* to hive@"dn01" identified by "hive" with grant option;

> use mysql

>select user,host from user;
>exit

1. dn01 노드의 root 계정에서
# cd /tmp

# wget http://apache.mirror.cdnetworks.com/hive/hive-2.3.7/apache-hive-2.3.7-bin.tar.gz
# tar xzvf apache-hive-2.3.7-bin.tar.gz
# mkdir -p /opt/hive/2.3.7

# mv apache-hive-2.3.7-bin/* /opt/hive/2.3.7/

# ln -s /opt/hive/2.3.7 /opt/hive/current

# cd /opt/hive

2. Hive 폴더 접근 권한 설정
[root@dn01 ~]# chmod -R 775 /opt/hive/2.3.7/
[root@dn01 ~]# chown -R hadoop:hadoop /opt/hive/

3. Hadoop 계정으로 전환
[root@dn01 ~]# su - hadoop

4. HIVE 환경 변수 추가
[hadoop@dn01 ~]# vi ~/.bash_profile
끝부분에 추가
#### HIVE 2.3.7 #######################
export HIVE_HOME=/opt/hive/current
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=.:${JAVA_HOME}/lib:${JREHOME}/lib:/opt/hive/current/lib
#### HIVE 2.3.7 #######################

저장 후 확인
[hadoop@dn01 ~]# source .bash_profile

5. HIVE 설정 파일 복사
[hadoop@dn01 ~]# cp /opt/hive/current/conf/hive-env.sh.template /opt/hive/current/conf/hive-env.sh
[hadoop@dn01 ~]# cp /opt/hive/current/conf/hive-default.xml.template /opt/hive/current/conf/hive-site.xml

6. HIVE 설정 파일 수정 ( 해당 부분을 찾아서 수정 - 제발 오타 확인!!!!! )
[hadoop@dn01 ~]# vi /opt/hive/current/conf/hive-env.sh
HADOOP_HOME=/opt/hadoop/current

[hadoop@dn01 ~]# vi /opt/hive/current/conf/hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.56.102:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>

5929줄이기때문에 /ConnectionURL 로 찾아간다.
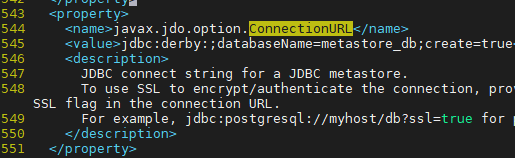
이 부분을

value 값을
jdbc:mysql://192.168.56.102:3306/hive?createDatabaseIfNotExist=true
로 바꾼다
다음은 /ConnectionDriverName을 찾는다

똑같이 value 값을
com.mysql.jdbc.Driver
로 바꾼다

다음은 /ConnectionUserName을 찾아

value를
hive
로 바꾼다

다음은 /ConnectionPassword 다음 검색내용을 보려면 n을 누르면 된다.

value를
hive
로 바꾼다.

다음은 /local.scratchdir 로

value를
/home/hadoop/iotmp
로 바꾸고

바로 그 뒤에 있는 resources.dir의 value를

/home/hadoop/iotmp
로 바꾸고

/current.db 로

찾아가 value를
true
로 바꾼다.

7. HIVE 관련 디렉토리 생성 및 권한 변경
[hadoop@dn01 ~]# mkdir -p /home/hadoop/iotmp
[hadoop@dn01 ~]# chmod -R 775 /home/hadoop/iotmp/

8. MYSQL Connector 다운로드 및 hive lib로 복사
[hadoop@dn01 ~]# cd /tmp
[hadoop@dn01 tmp]# wget http://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.38.tar.gz

[hadoop@dn01 tmp]# tar xzvf mysql-connector-java-5.1.38.tar.gz

[hadoop@dn01 tmp]# cd mysql-connector-java-5.1.38
[hadoop@dn01 mysql-connector-java-5.1.38]# mv mysql-connector-java-5.1.38-bin.jar /opt/hive/current/lib/

9. HIVE 기본 디렉터리 생성 및 권한 추가
nn01에서 start-all.sh로 하둡을 켜놓은 상태여야 한다.
[hadoop@dn01 ~]# hdfs dfs -mkdir /tmp
[hadoop@dn01 ~]# hdfs dfs -mkdir -p /user/hive/warehouse
[hadoop@dn01 ~]# hdfs dfs -chmod -R 777 /tmp
[hadoop@dn01 ~]# hdfs dfs -chmod -R 777 /user/hive/warehouse

10. HIVE mysql 기본 스키마 생성
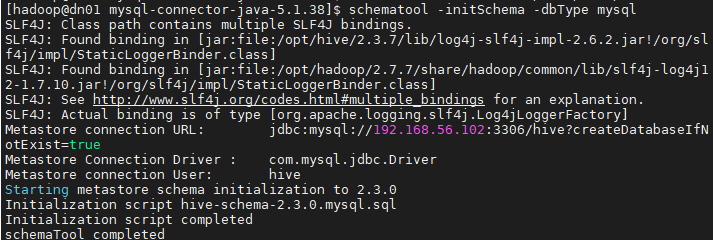
[hadoop@dn01 ~]# schematool -initSchema -dbType mysql
( 에러가 발생한다면 기존에 같은 이름의 데이타베이스가 있으니깐
show databases에서 drop database hive; 제거 )
11. HIVE 접속
[hadoop@dn01 ~]# hive
( hive 실행전에 메타스토어를 초기화 해야 한다. 즉 10번 하고 hive 명령어 실행 )
브라우저에서 http://192.168.56.101:50070
메뉴 > Utitlies > Browser Directory >
/
user
hive
warehouse 에서 앞으로 확인

12. beeline 접속하기 위한 추가 작업
beeline은 그룹과 유저가 other이기 때문에
* 모든 노드의 core-site.xml 에 수정 :
모든 그룹과 호스트에게 접속하기 위한 관문역할의 proxy를 모두가 가능하도록 변경
nn01에서
# cd $HADOOP_HOME/etc/hadoop

# vi core-site.xml
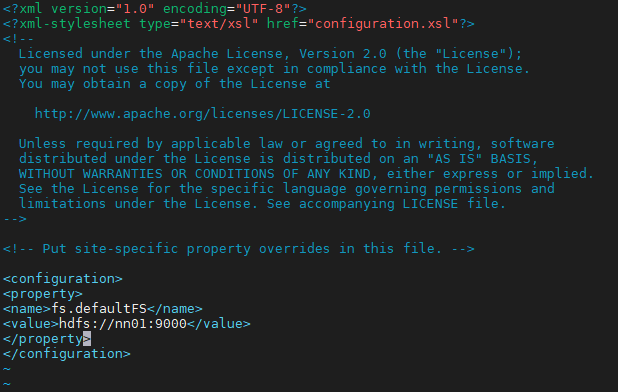
마지막 </property> 뒤에
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
추가

* beeline은 others 권한으로 접속하므로, HDFS 권한을 수정해준다.
# hdfs dfs -chmod -R 777 /tmp
# hdfs dfs -chmod -R 777 /user/hive/warehouse
core-site.xml 수정하여 dn01, dn02에 복사.
# scp core-site.xml hadoop@dn01:/opt/hadoop/current/etc/hadoop
# scp core-site.xml hadoop@dn02:/opt/hadoop/current/etc/hadoop

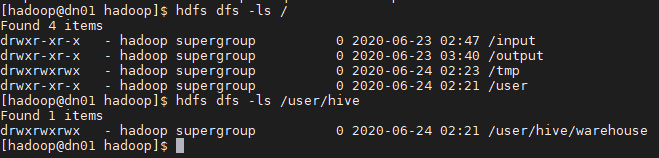
# hdfs dfs -ls /
# hdfs dfs -ls /user/hive
로 권한 확인


-----------------mariadb.service중인지 확인------------------

active가 아니면 켜줘야한다.
hive에 데이터 넣기
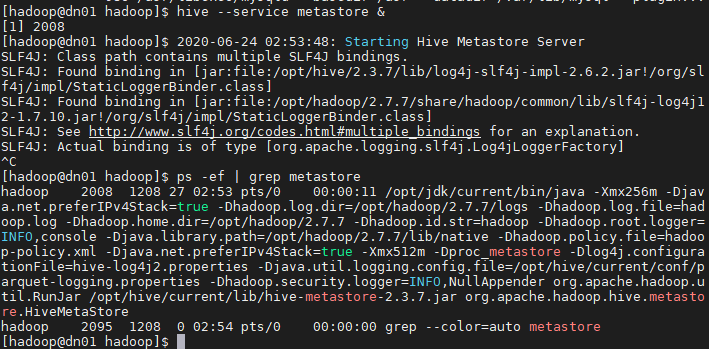
# hive --service metastore & (metastore를 백그라운드로 실행)
# ps -ef | grep metastore
# hive --service hiveserver2 &
# ps -ef | grep hiveservice2

# hive
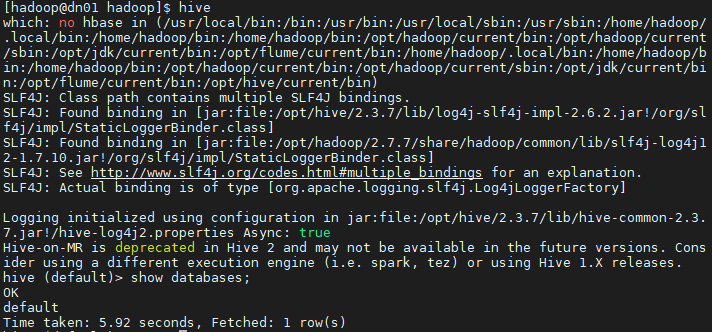
> create database sample1;
> show databases;
> use sample1;

> create table emp(name string);
> insert into emp(name) values ("PARK");

에 들어가 /user/hive/warehouse를 확인하면

db가 생겼다.

dn02에서 dn01로 접속
# ssh dn01
# hdfs dfs -ls /user/hive/warehouse/sample1.db/emp

# hdfs dfs -cat /user/hive/warehouse/sample1.db/emp/000000_0

내용을 확인할 수 있다.
belline 데이터 넣기
dn01에서
# beeline
> !connect jdbc:hive2://
hive
hive

> show databases;
> use sample1;
> insert into emp(name) values("KIM")

> select * from emp;
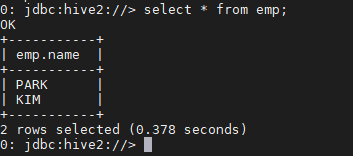
> !quit
로 beeline을 나올 수 있다.

hive에 데이터 입력
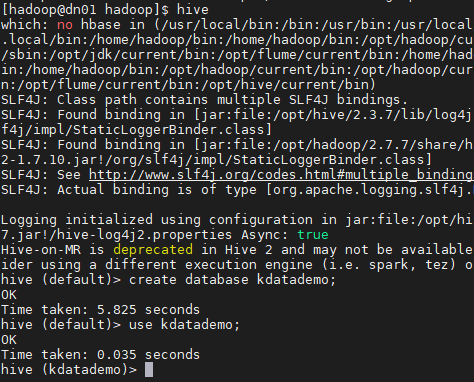
# hive
> create database kdatademo;
> use kdatademo;


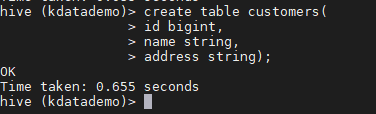
> create table customers(
> id bigint,
> name string,
> address string);
> desc customers;

insert into customers values
( 1111, "John", "WA" ),
( 2222, "Emily", "WA" ),
( 3333, "Rick", "WA" ),
( 4444, "Jane", "CA" ),
( 5555, "Amit", "NJ" ),
( 6666, "Nina", "NY" );

> select * from customers;

create table if not exists orders(
id bigint,
product_id string,
customer_id bigint,
quantity int,
amount double);

insert into orders values
(111111, "phone", 1111, 3, 1200 ),
(111112, "camera", 1111, 1, 5200 ),
(111113, "notebook", 1111, 1, 10 ),
(111114, "bag", 2222, 2, 20 ),
(111115, "t-shirt", 4444, 2, 66 );
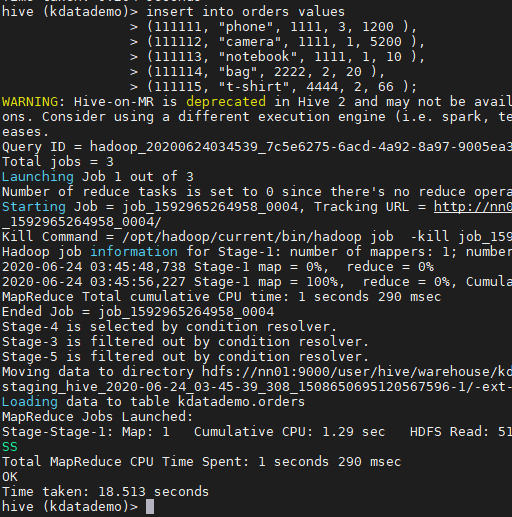
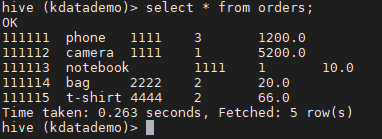
> select * from orders;
* [ 연습 ]
- 주소가 WA인 고객 검색

- 주소가 WA이면서 id가 2222보다 큰 고객 명단

- 고객테이블에서 주소컬럼 검색

- 주소로 정렬하여 고객명과 주소 검색

- 고객명단 수 검색

- 첫번째 고객명단 검색 ( mysql 문법 )

- 주소별 인원수 검색

- 고객아이디, 고객명과 고객이 주문한 상품명 출력
