- [하둡] 플룸으로 bitthumb api 데이터 수집2020년 06월 23일
- 홀쑥
- 작성자
- 2020.06.23.:44
10초마다 bitthumb의 public api에서 값을 받아와 하둡에 올린 뒤
hadoop에서 쉘 스크립트로 주기적 실행


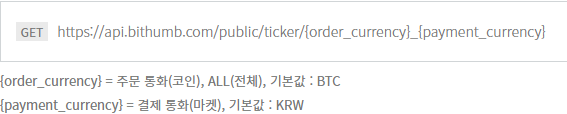
https://apidocs.bithumb.com/docs/ticker
No.1 가상자산 플랫폼, 빗썸
비트코인, 이더리움, 비트코인캐시, 리플, 라이트코인, 대시, 모네로, 비트코인골드, 이오스, 이더리움클래식, 퀀텀, 제트캐시, 실시간 시세, 쉽고 안전한 거래
www.bithumb.com
api로 값을 받아오면

이런식으로 JSON형식으로 값을 받아옴
1. Maven 프로젝트 만들기



2. pom.xml덮기
3. temp폴더 옮기기

4. Maven - > update Project 후 Run as -> maven Install (2번)

5. winSCP에서 dn01에 jar 파일 옮기기

6. dn01에서 작업




파일에는 0 하나만 입력 후 저장

flume-bitcoin.properties 에 다음와 같이 입력 후 저장
agent.sources = s1 agent.channels = m1 agent.sinks = h1 # For each one of the sources, the type is defined agent.sources.s1.type = taildir # The channel can be defined as follows. agent.sources.s1.channels = m1 agent.sources.s1.filegroups = f1 agent.sources.s1.filegroups.f1 = /home/hadoop/source_data/bitthumbitCoin/bitthumbitCoin[0-9]{1,}.csv # spool dir #agent.sources.s1.taildir = /home/hadoop/source_data/bitthumbitCoin/ #agent.sources.s1.inputCharset = UTF-8 # Each sink's type must be defined agent.sinks.h1.type = hdfs #Specify the channel the sink should use agent.sinks.h1.channel = m1 agent.sinks.h1.hdfs.path = hdfs://nn01:9000/user/hadoop/testInput/bitThumb agent.sinks.h1.hdfs.writeFormat = Text agent.sinks.h1.hdfs.rollSize = 64000000 agent.sinks.h1.hdfs.rollInterval = 0 agent.sinks.h1.hdfs.rollCount = 0 agent.sinks.h1.hdfs.batchSize = 9900 agent.sinks.h1.hdfs.fileType = DataStream # Each channel's type is defined. agent.channels.m1.type = memory # Other config values specific to each type of channel(sink or source) # can be defined as well # In this case, it specifies the capacity of the memory channel agent.channels.m1.capacity = 10000 agent.channels.m1.transactionCapacity = 10000저장 후 확인
플룸 실행
#

플룸을 실행하는 동안에는 dn01 작업할 수 없음
dn02에서 dn01로 가서 작업



java 시작

확인 후 nn01에서 dn01로 접속


tmp는 시간이 지나 csv과 꽉 차서 저장되면 사라진다 
좀 이따 다시 확인해보면



파일이 생성되어있다.
다음글이전글이전 글이 없습니다.댓글
스킨 업데이트 안내
현재 이용하고 계신 스킨의 버전보다 더 높은 최신 버전이 감지 되었습니다. 최신버전 스킨 파일을 다운로드 받을 수 있는 페이지로 이동하시겠습니까?
("아니오" 를 선택할 시 30일 동안 최신 버전이 감지되어도 모달 창이 표시되지 않습니다.)