- [하둡] 하둡 설치 (2)2020년 06월 22일
- 홀쑥
- 작성자
- 2020.06.22.:14
https://thinmug.tistory.com/24

로그아웃으로 su로 로그인 계정을 로그아웃하고 다시 root로 갈 수 있다.
멀티환경을 해제하고
# vi /etc/pam.d/su


10~ 12번 째 줄 주석
모든 가상머신 전부 똑같게 하기 (환경 설정할 때는 멀티환경을 왠만하면 쓰지 않는다)

이제 su로 root계정에 갈 수 있다.
하둡, 자바 환경변수 설정
하둡계정에서
# vi ~/.bash_profile
이후 멀티를 푼다. (오류예방)
Shift G로 맨 끝으로 이동 후 o 단축키로 다음줄로 이동 다음 오른쪽밑에 글을 그대로 복사해서
오른쪽클릭하면 복사가 된다.
3가상머신 모두 입력
#### HADOOP 2.7.7 start ############
PATH=$PATH:$HOME/bin
export HADOOP_HOME=/opt/hadoop/current
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#### HADOOP 2.7.7end################ JAVA 1.8.0 start#############
export JAVA_HOME=/opt/jdk/current
export PATH=$PATH:$JAVA_HOME/bin
#### JAVA 1.8.0 end##############
3개의 가상머신 다 똑같이 만든다 환경변수를 잡으면 다른 곳에서도 환경변수 설정한 파일들을 사용할 수 있다.
다시 멀티버전으로 설정하고
# source ~/.bash_profile 로 설정파일 적용
이 후 버전 확인
# java -version
# java version

확인하기 위해 Hello.java를 만들어 컴파일하고 실행해봤다.

Hello.java 
javac, java Data Node와 NameNode는 통신이 자유로워야한다.
비밀번호없이 각노드를 접속할 수 있도록 공개키 공유(SSH)
먼저 VirtualBox에서 직접 작업해야하기에 nn01먼저 시작
root경로로
# vi /etc/hosts

3 dd로 모든 내용 다 지우고
192.168.56.101 nn01
192.168.56.102 dn01
192.168.56.103 dn02
입력하고 저장
모든 가상머신에 다 똑같이 입력 후 저장

이제 hadoop계정에서 키를 만들어 각자에게 보내줘야한다.
다시 멀티 모드로 작업
# su - hadoop

# ssh-keygen

입력창이 나오면 전부 엔터
키 값이 생성된다
이제 키를 복사한다.
[hadoop@nn01 ~]$ ssh-copy-id hadoop@dn01
[hadoop@nn01 ~]$ ssh-copy-id hadoop@nn01
[hadoop@nn01 ~]$ ssh-copy-id hadoop@dn02
[hadoop@dn01 ~]$ ssh-copy-id hadoop@dn01
[hadoop@dn01 ~]$ ssh-copy-id hadoop@nn01
[hadoop@dn01 ~]$ ssh-copy-id hadoop@dn02[hadoop@dn02 ~]$ ssh-copy-id hadoop@dn01
[hadoop@dn02 ~]$ ssh-copy-id hadoop@nn01
[hadoop@dn02 ~]$ ssh-copy-id hadoop@dn02yes 후에 비밀번호 (hadoop) 입력
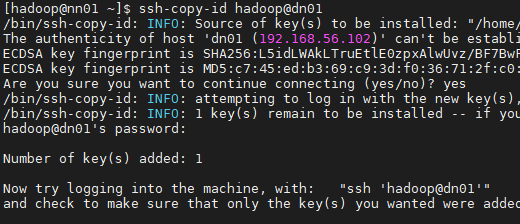
이렇게 다 반복한다.
다 완료했으면 이제 패스워드없이 이동이 가능하다. ( 나올 때는 exit 또는 logout 으로 나온다 )

ssh nn01,dn01,dn02를 눌러보면 비밀번호 입력 없이 바로 로그인이 가능하다.
다른 계정들도 전부 확인해본다.
하둡 설정
먼저 멀티하고 파일열때는 같이, 쓸때만 풀고 쓴다.
# vi /opt/hadoop/current/etc/hadoop/core-site.xml

<configuration> 안에
<property>
<name>fs.defaultFS</name>
<value>hdfs://nn01:9000</value>
</property>저장하고
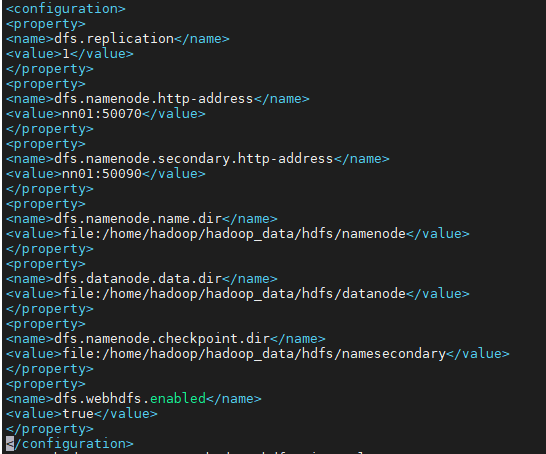
# vi /opt/hadoop/current/etc/hadoop/hdfs-site.xml
<configuration> 안에
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>nn01:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>nn01:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/home/hadoop/hadoop_data/hdfs/namesecondary</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>추가
# vi /opt/hadoop/current/etc/hadoop/yarn-site.xml
<configuration> 안에
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>nn01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>nn01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>nn01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nn01</value>
</property>
# cp /opt/hadoop/current/etc/hadoop/mapred-site.xml.template /opt/hadoop/current/etc/hadoop/mapred-site.xml

# vi /opt/hadoop/current/etc/hadoop/mapred-site.xml
<configuration> 안에
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.hosts.exclude.filename</name>
<value>$HADOOP_HOME/etc/hadoop/exclude</value>
</property>
<property>
<name>mapreduce.jobtracker.hosts.filename</name>
<value>$HADOOP_HOME/etc/hadoop/include</value>
</property>
저장
# vi /opt/hadoop/current/etc/hadoop/masters

nn01입력 후 저장
# vi /opt/hadoop/current/etc/hadoop/slaves
에서 원래 있던 localhost를 지우고
dn01
dn02 입력 후 저장
# vi /opt/hadoop/current/etc/hadoop/hadoop-env.sh

이부분을
export JAVA_HOME=/opt/jdk/current로 바꾼다

# vi /opt/hadoop/current/etc/hadoop/yarn-env.sh
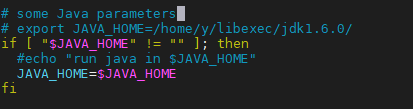
에서
# some Java parameters 밑에
export JAVA_HOME=/opt/jdk/current 추가

만약 ModaXterm으로 작업하기 어려우면
hadoop설정을 nn01에서하고 dn01과 dn02에 복사 (winscp툴을 이용하거나 scp명령을 이용한다.
혹은
[nn01(root 계정)]
a. [root@nn01 ~]# scp -r /opt/hadoop/* dn01:/opt/hadoop
a. [root@nn01 ~]# scp -r /opt/hadoop/* dn02:/opt/hadoop
[dn01(root 계정)] 심볼릭링크와 소유자를 다시 설정한다.
a. [root@dn01 ~]# rm -rf /opt/hadoop/current
b. [root@dn01 ~]# ln -s /opt/hadoop/2.7.7 /opt/hadoop/current
c. [root@dn01 ~]# chown -R hadoop:hadoop /opt/hadoop/
[dn02(root 계정)] 심볼릭링크와 소유자를 다시 설정한다.
a. [root@dn02 ~]# rm -rf /opt/hadoop/current
b. [root@dn02 ~]# ln -s /opt/hadoop/2.7.7 /opt/hadoop/current
c. [root@dn02 ~]# chown -R hadoop:hadoop /opt/hadoop/이제 따로 작업하기위해 멀티를 끈다.
그리고 nn01계정에서
# mkdir -p ~/hadoop_data/hdfs/namenode
# mkdir -p ~/hadoop_data/hdfs/namesecondary
NameNode디렉토리와 NameSecondary 디렉토리 만들기 dn01, dn02에서 각각
# mkdir -p ~/hadoop_data/hdfs/datanode 를 입력한다.


하둡 NameNode 포맷
nn01에서
# hadoop namenode -format


nn01에서
# start-all.sh

# stop-all.sh로 멈추기 (나중에 끄는것도 일, save모드에 들어간 거 종료하기 힘듬)
몇가지가 안나오면
root계정에서
# chown -R hadoop:hadoop /home/hadoop
오류찾기
[hadoop@nn01 current]$ ls -al /opt/hadoop/current/logs/모든 전원을 다 끄고 (VirtualBox, 등등 모두)
다시 켰을때 start-all.sh가 잘 되면 성공
VirtualBox를 다 끄고 다시 실행시킨 뒤

hadoop 계정으로 로그인 후 nn01에서 start-all.sh

하둡이 켜진 뒤 jps명령어를 입력했을 때

성공적으로 뜨면 stop-all.sh하고 나가기
설치 끝
다음글이전글이전 글이 없습니다.댓글